


This is the tenth and final guide in a series of new guides brought to you by
It’s hard for me to believe, but we have come to the end of this little series. I hope you have at least picked up one small trick or idea along the way that makes your life easier or improves your users’ experience.
I could not in good conscience wrap this up without discussing maybe the most important topic that always seems to be overlooked or fall under “We will take care of that later when there is time”: monitoring and maintenance.

It is not the flashiest of topics, and your end users won’t praise you for doing a good job of monitoring directly. That being said, if you develop a robust plan for monitoring and respond to it well, your users will not know when things break and they won’t need to contact support for help. Additionally, you can usually fix or update items at a more leisurely pace and avoid emergency fixes, which is always a plus (don’t live in the fire).
I am going to cover a couple of the techniques I typically employ, and while this is not a complete list, please use it as a jumping off point to make sure you are thinking about how to properly manage and monitor each new process you might build. Leveraging things like the API and webhooks are great, but as most comic book fans know...

To emphasize the importance of this, when I am scoping out the timeline for a new development, I usually calculate the build and testing time. I then add 50% of that time to the total for the project proposal. This is to be split between documentation and making sure proper monitoring is configured. Since it is baked into the agreed upon development time, managers are less likely to say “do that later, we need X first”. My motto when it comes to this is “the project is not complete until I can be hit by a bus and there will be no issues.”
Guide Table of Contents
Tracking Scheduled Reports
Many of the processes we discussed either use or could use scheduled reports from the system. This is great and helps mitigate the use of large amounts of API calls. However, this means that the report running becomes a vital part of the system. While this should be understood to just work, the reality is sometimes a glitch or bad update or large background job request can cause the reports to queue and your processes to not run—or even fail.
Here’s how I approach this (as an overview):
-
The scheduled reports are emailed to a ‘donotreply’ inbox that is leveraged for many automations.
-
Copy the reports to a SharePoint site, with a separate folder for each report type.
-
Every set period of time a Power Automate Flow runs. It is configured to do the following
-
Use the ‘Get Files(properties only) SharePoint’ action to filter for files in the SharePoint folder that were created in the last X period of time.
-
Check to see if any results were returned.
-
If no files are found, send an alert to the appropriate users to investigate.
-
Tip: I usually start with once a day checks. If it is more important or having continual issues, move this recurrence up as is appropriate.
This can also work similarly using the automation app and FTP files hosted on a server. Just change the SharePoint look ups to look at the FTP server to make sure the files either exist or have been updated within a certain time frame.
Tracking API Usage for Being Updated/Deprecated
This was briefly covered in the second article, but it bears repeating. If you are building processes using API endpoints, you need to keep track of which processes are using which endpoints. If you think you will remember, you won’t, and so many endpoints are similar looking—it is easy to mix them up. APIs change, break, get updated, and eventually get deprecated. This means it is vital to be aware of which ones you are using and where. I highly recommend some sort of tracker that shows you at least the following:
-
The endpoint URL
-
The type of API (POST, GET, DELETE, or PUT)
-
Where it is used (I name my workflows, so I use the names from the API Browser, but coming up with a method that is easy to tie back where it is used is important.)
-
When it is used (If it is scheduled, mark the hours of the day it runs.)
Here is an example of a simple Excel file I use:
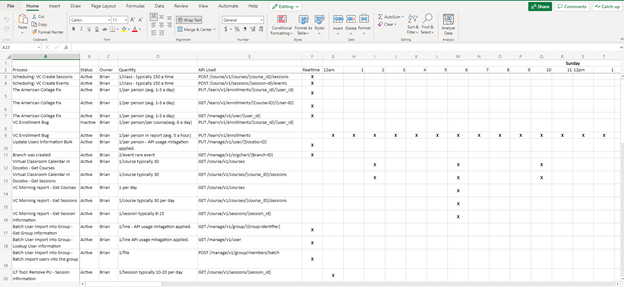
This is useful in multiple ways:
-
It is a great document for collaboration with teammates to keep an eye on everything and passing knowledge on as you move on to other positions.
-
When building new workflows that you want to schedule, you can see which hours are already being used too much and find appropriate times.
-
Most importantly, you can easily search the endpoints called out in the Docebo monthly notices that will be updated or deprecated to see if there is any imminent impact to your systems. This lets you plan accordingly to make the appropriate changes before they go into effect.
If you do not read these monthly updates, take a minute now to go subscribe to them here. They are a great resource provided by Docebo.
Process Failure Notices
When building your processes, any platform you are using should have some method to alert you when a part or the whole process fails. Make sure to dig in to find out how and utilize it. Below is how I approach this in my setup of Flows in Power Automate, but the general concept applies to many setups.
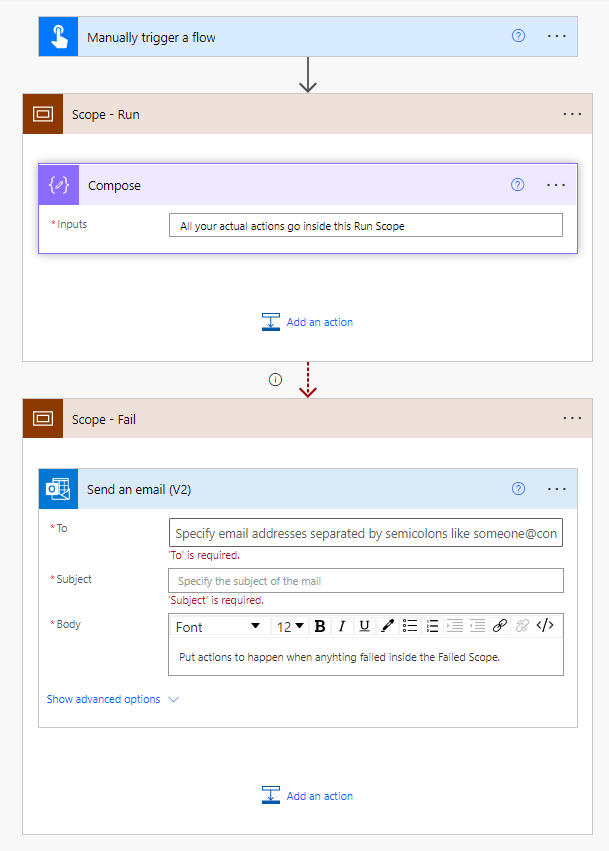
The Flow is configured into 3 main segments:
-
Trigger & Setup: This is where the mechanism that starts the Flow is held and any variables that need to be initialized live.
-
Run Scope: Everything related to running the process is put within this scope wrapper. By doing this, we can easily send a signal if any individual piece within the scope fails.
-
Fail Scope: This scope wrapper only runs if the Run Scope sends a failure notice. This is configured by using the ‘configure run after’ settings on the Fail Scope element.
Typically a ‘Send email’ or ‘Post message to Teams’ (or both) is put within the Fail Scope so that the appropriate users can be notified there was a problem and can immediately investigate.
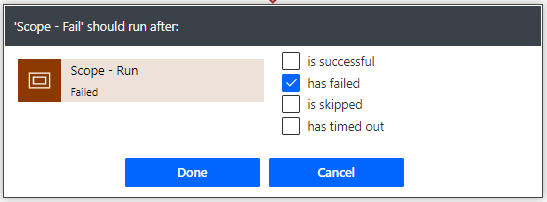
There may be times when you want to know when a specific part or action within the ‘Run Scope’ fails. You can add additional ‘Send email’ or ‘Post message to Teams’ notices directly to a specific step, but they will only run if that step fails.
Monitoring the API Limit and Usage
The API is only guaranteed to function and perform as expected when using 1,000 calls per hour per IP address. Try more than this and you could see undesired behaviors. This is not that large of a limit if you begin to build complex applications. While this is a soft limit, it is best to try and respect it as best you can to make sure you do not cause issues on your platform.
When I am building workflows in Power Automate that use a lot of calls regularly throughout the day, I build in two things to each of these flows:
-
A check at the start of the flow to see if a variable I have stored in a SharePoint list (shared by all of my workflows) is less than 1,000. If it is not, then it waits until the next hour to check again and potentially run.
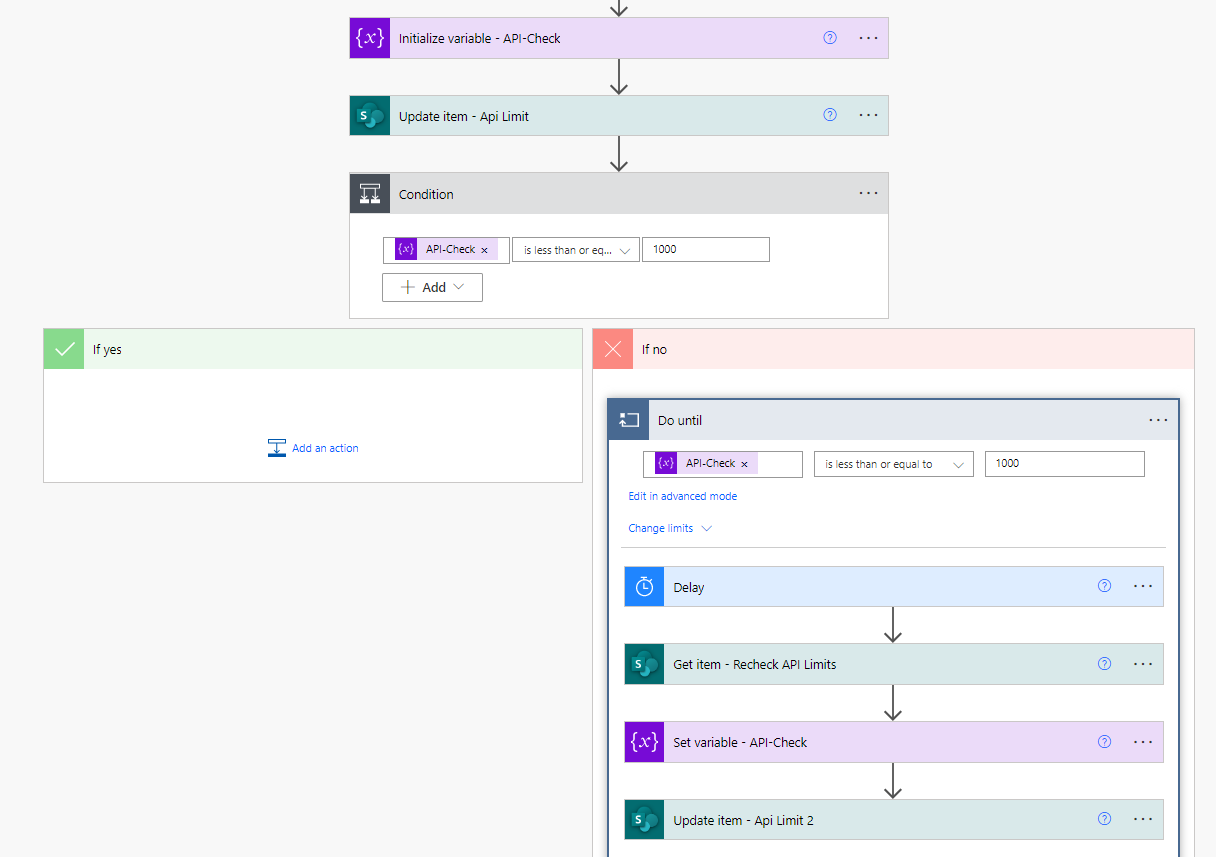
-
At the end of any workflow, it updates that same SharePoint variable with how many calls were used by this run of the flow.

The variable gets reset to 0 every hour to restart the count. This has been very effective, and I can rest easy that I am not abusing the service and causing issues.
Keep in mind that if you are frequently finding a particular time of day that you are using more calls, use the API tracking chart recommended above to see if any processes can be shifted to hours that have less usage. I also sometimes assess whether to use an API or an alternative, like a report, to accomplish what I need for the process. It is a constant game of balance. Remember that just because you can do something, it does not mean you should or that it is the best path forward.
What’s Next?
And now, my community friends, we have come to the end. I have had a blast putting this series together and hope you have found some value in it. This does not mean things are over—as you may know, I have another ongoing guide series about quick and easy API solutions.
In the meantime, if there’s any topic or issue you wish had been covered or details you wish were gone into, please let me know in the comments! I will absolutely be watching and taking them into account.

Guide Series:
The Art of Being Lazy: Leveraging the API to Take Care of Repetitive Tasks & Fill Feature Gaps
Getting Started: Building Out Your Toolbox [Part 1] and [Part 2]
Reports: Sending, modifying, and more!
In the Room When it Happens: Act On Events with Webhooks
Bulk Scheduling ILT Sessions with a CSV File
Tag, You’re It!: Tracking and Managing Content Tags
Let Others Do It: The Power of Forms in a Workflow
And We're Back: How to Let Users have a Form as a Wizard Scheduling Tool
You Built It, They Came, Now What?: Scheduling ILT Wizard Bonus Activities
