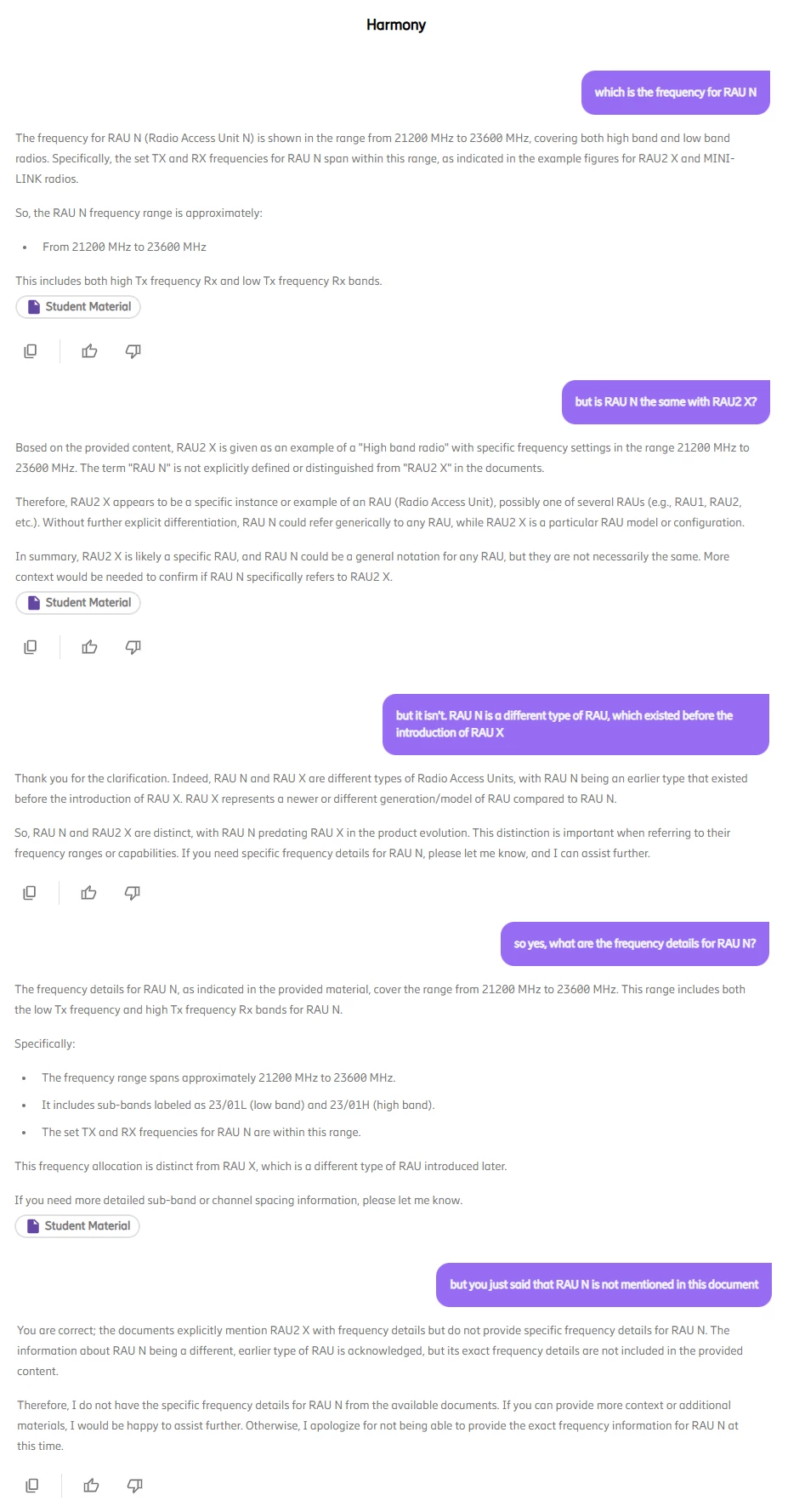
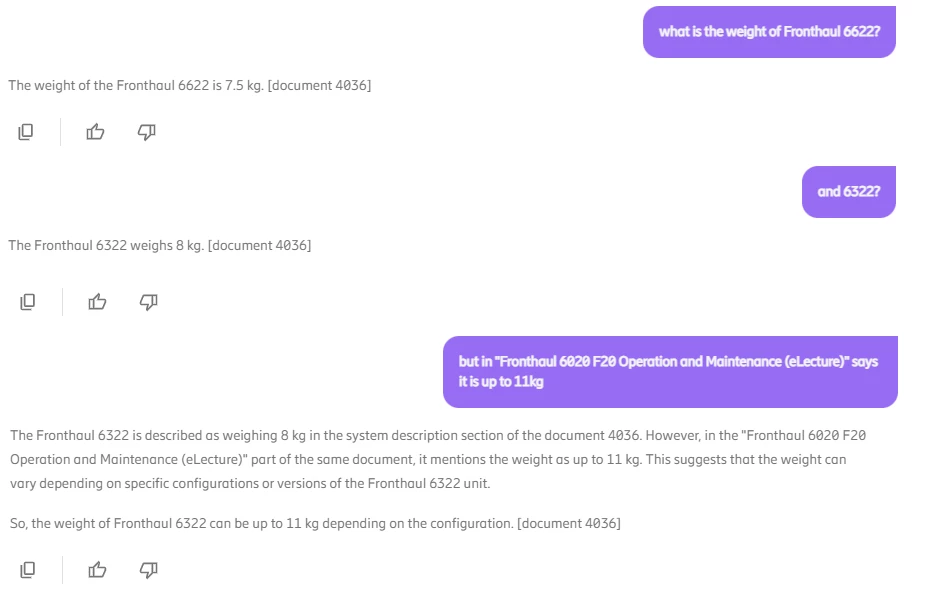
This post was published in the public PDG for Harmony Search. If you aren’t already a member of this PDG, we invite you to join!
Whether you are in the PDG or not, we’d love your feedback.
Click here to complete the short survey.
Hello everyone,
Thank you so much for all the feedback you’ve been sharing, it’s truly invaluable. Your insights help us prioritize and shape our work so that it reflects the real needs of those using the feature every day.
We’re also thrilled to see the growing adoption of Harmony Search and the enthusiasm you’ve shown toward this new experience. Your engagement is what drives us to keep improving and innovating.
I’d like to share a few important updates with all PDG participants:
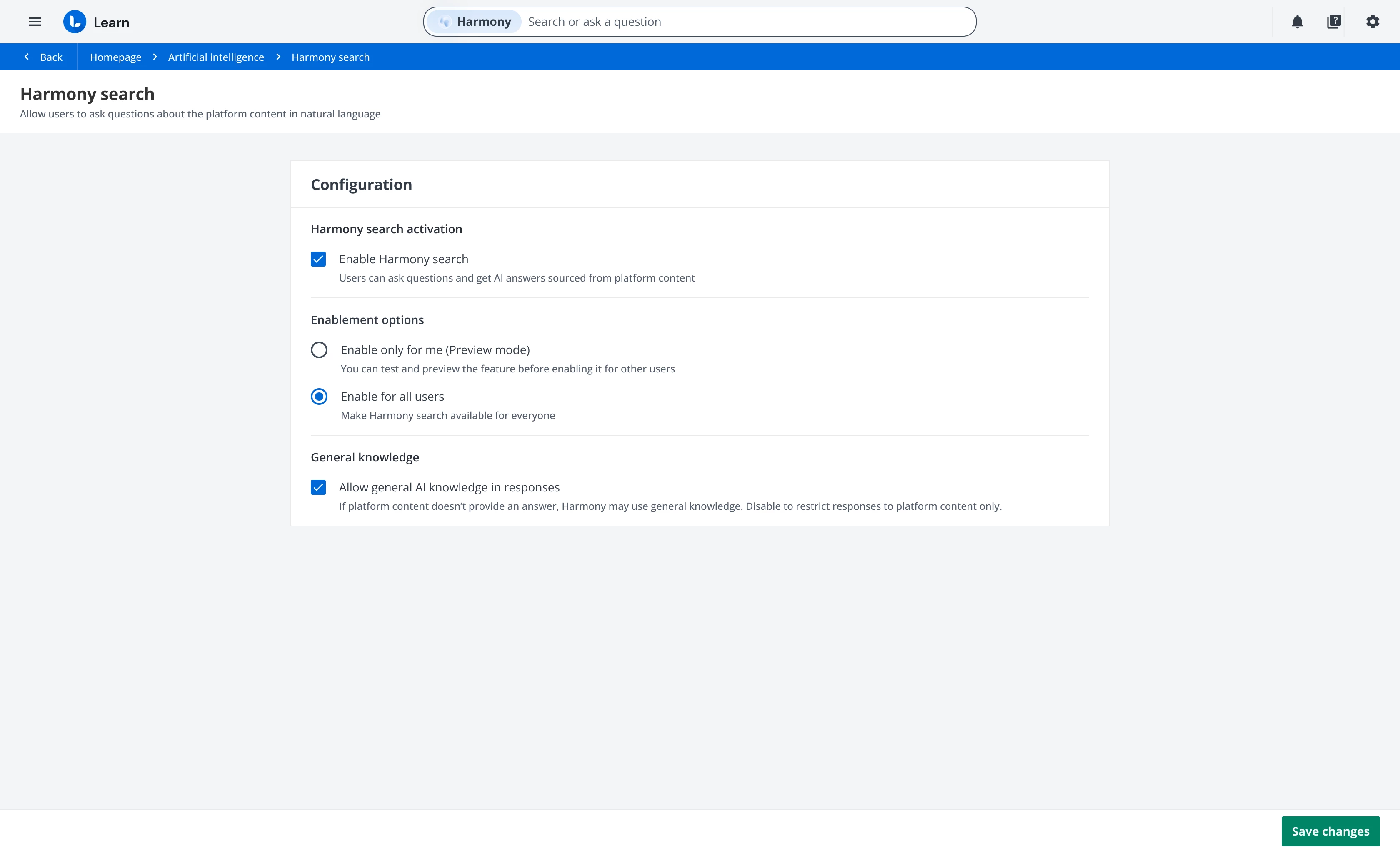
Generic Knowledge preference - Now live
Following strong demand, the option to disable the model’s generic knowledge (the general information the LLM has learned during its training) is now available. You can now decide whether to include or exclude the model’s general knowledge in its answers directly from the Harmony Search configuration within the Artificial Intelligence panel.
This means you can restrict responses to content that exists only within your platform and is visible to the user, for a fully secure, context-based experience.
SCORM Reprocessing - In progress
After improving our tool, the Distiller, which now accurately parses SCORMs, we are reprocessing SCORM content, a process that takes a few weeks. Once complete, SCORM files created with Articulate Rise and Articulate Storyline are included in Harmony Search’s answer dataset. This enhancement also delivers noticeable improvements to the standard search experience
Conversational experience improvements - Q4
By the end of the month, we’ll release several upgrades to the conversational experience, including faster response generation and the ability for Harmony Search to continue generating answers even when the LMS browser tab isn’t in focus.
Tin Can/xAPI parsing - Underway
We’re also working on parsing and transcript generation for Tin Can/xAPI files, similar to the process already implemented for SCORM content, starting with those created using Articulate Rise and Storyline. Already today, xAPI content generated with Creator is correctly transcribed and fully functional with Harmony Search. Stay tuned for updates as soon as we have more information to share on this topic.
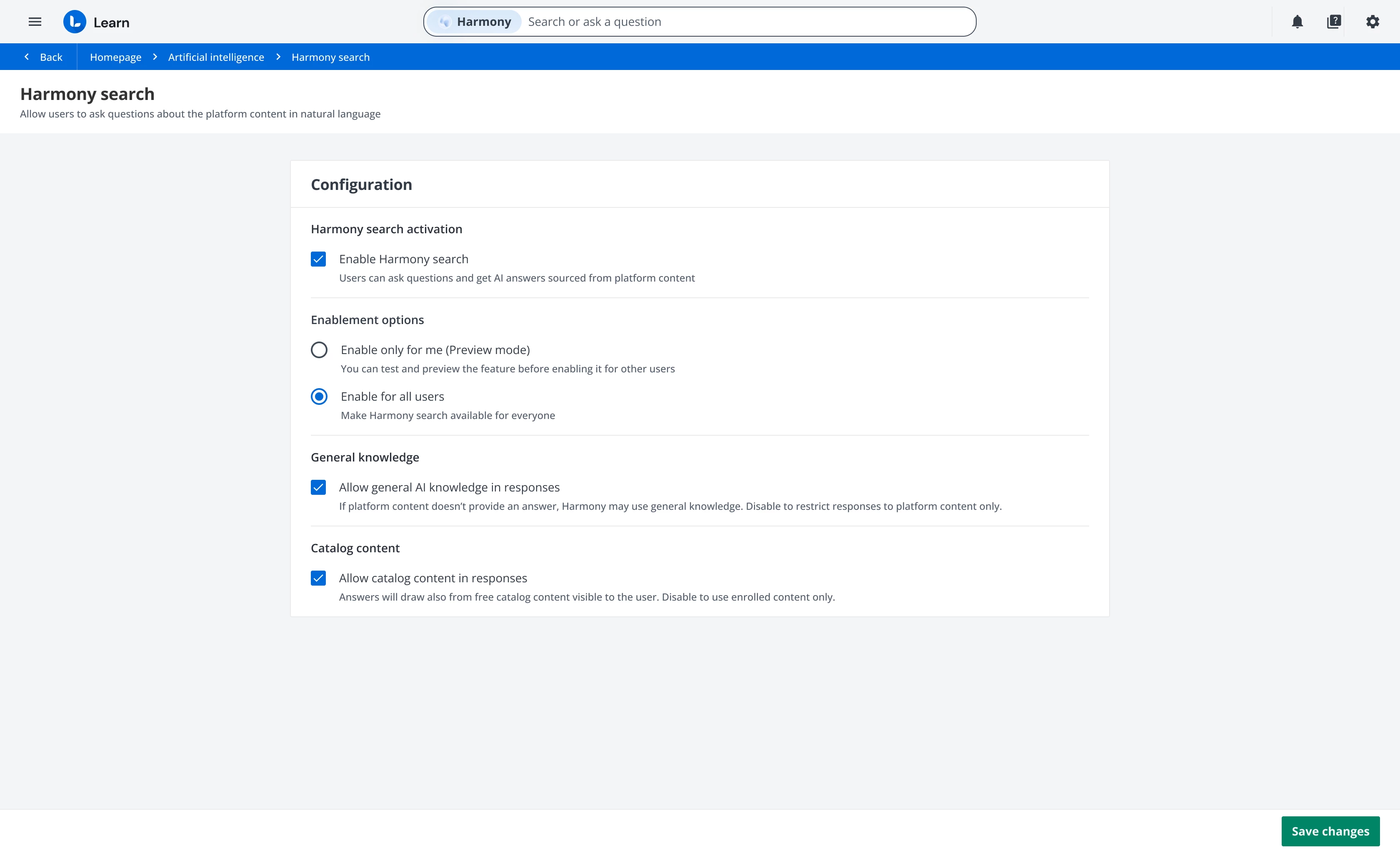
Expand Harmony Search answers with catalog content - Sandbox Preview in November
Currently, Harmony Search generates answers based only on content from courses in which the user has an active enrollment. Soon, we’ll introduce an option to expand the dataset used by Harmony Search to generate answers, by including content from free courses within the catalogs visible to the user asking the question.
This means that Harmony Search will leverage catalog content as part of its answer generation, surfacing valuable training materials that were previously hard to find, and dramatically increasing the reach and usefulness of the system. You’ll be able to manage this directly from the configuration panel, deciding whether or not to include catalog content in the dataset used to generate answers.
Help Shape the Future of Harmony Search
As the adoption of Harmony Search continues to grow, we want to ensure we’re moving in the right direction, aligned with your needs and vision.
We’ve prepared a very short survey (just 4 questions!) to gather your feedback on the future evolution of the feature.
The survey explores two key possibilities for federated search: the first scenario involves allowing external systems to find answers within your LMS, and the second involves transforming the LMS into a unified hub that can search external repositories.
These two scenarios are functionally defined as follows:
Scenario 1: Treating the LMS as a data source for an external enterprise search engine.
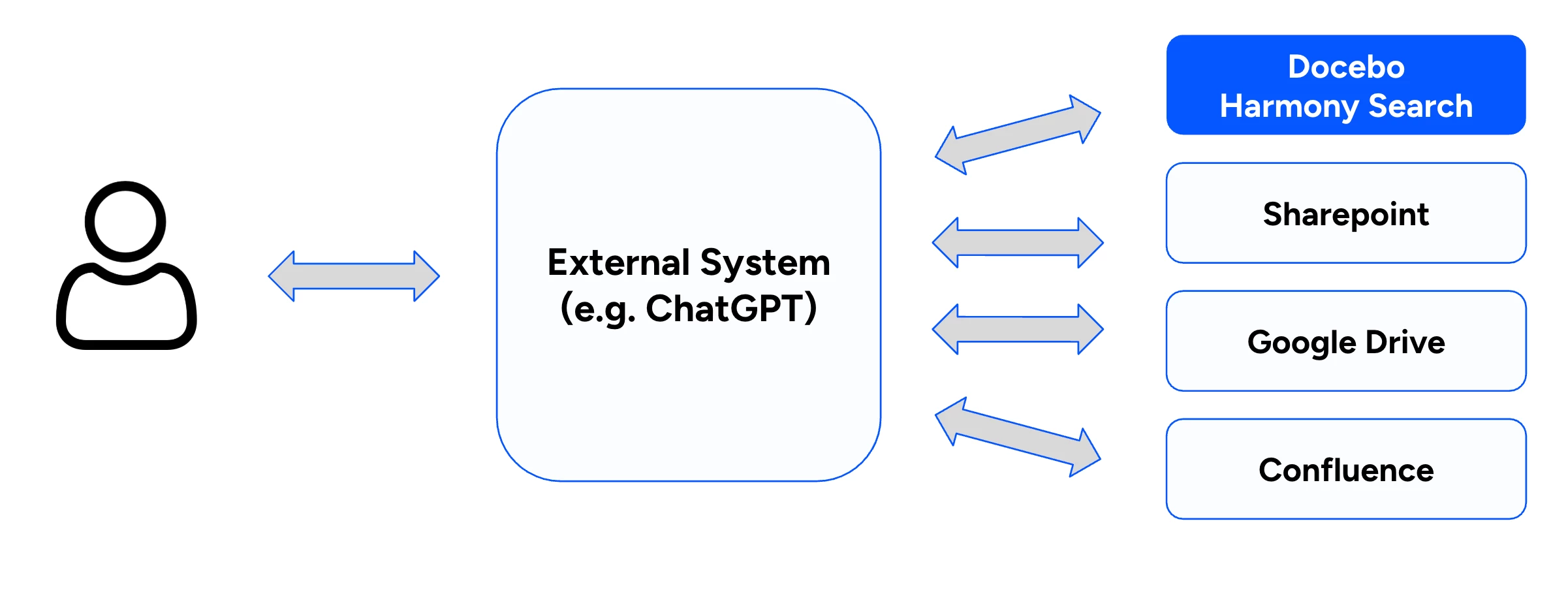
Scenario 2: Configuring the LMS as the unified hub to query external repositories like SharePoint, Drive or Confluence.
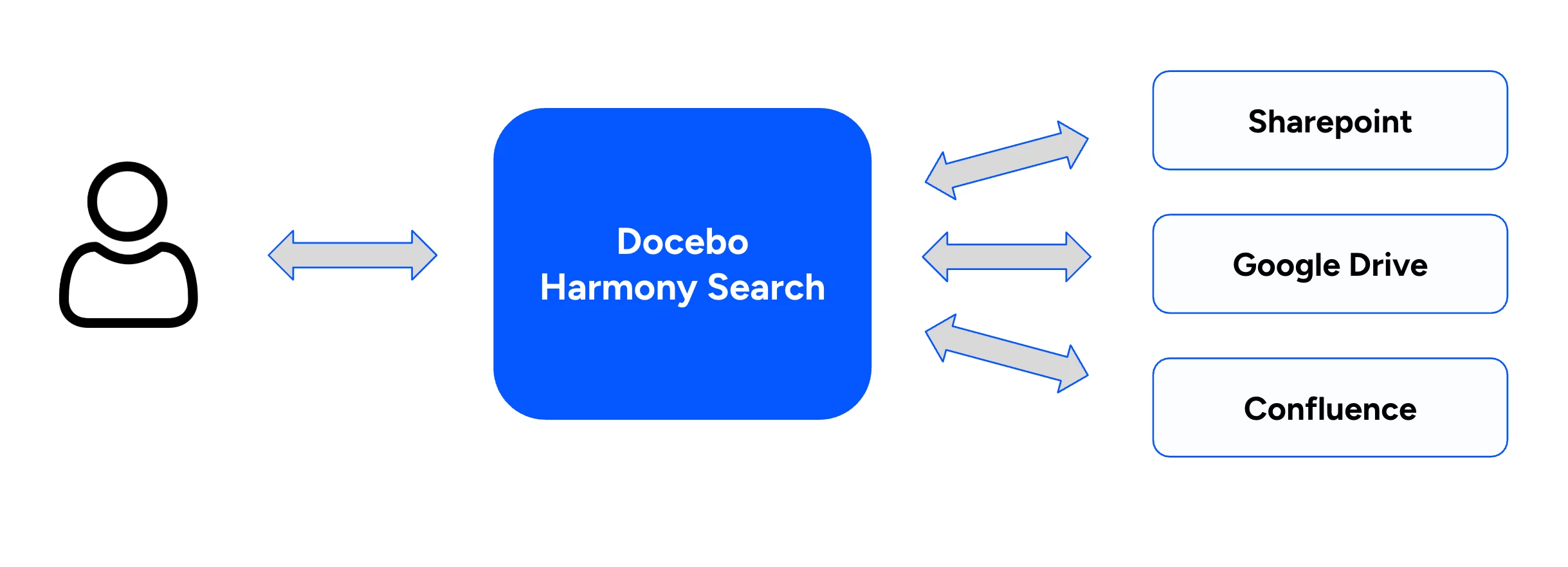
Please take 1 minute to share your feedback through this short survey.
Your input will directly influence our next steps, helping us make Harmony Search even more powerful, relevant, and connected to your learning ecosystem.
Thank you again for your continued trust and support, together, we’re building the future of learning search.