As you all know, fetching information about responses to surveys is a “bit” painful task, as there is no report or single UI allowing you to get it for multiple courses and/or surveys.
In our system we have course evaluation surveys added to each course (around 250 courses and counting), most of the courses use the same survey added from the central repository, however, some have their own surveys.
Of course tracking user responses, by navigating to each course and downloading the file is time consuming and is not a feasible solution, as we want to analyze feedback weekly and quickly react to any issues and comments.
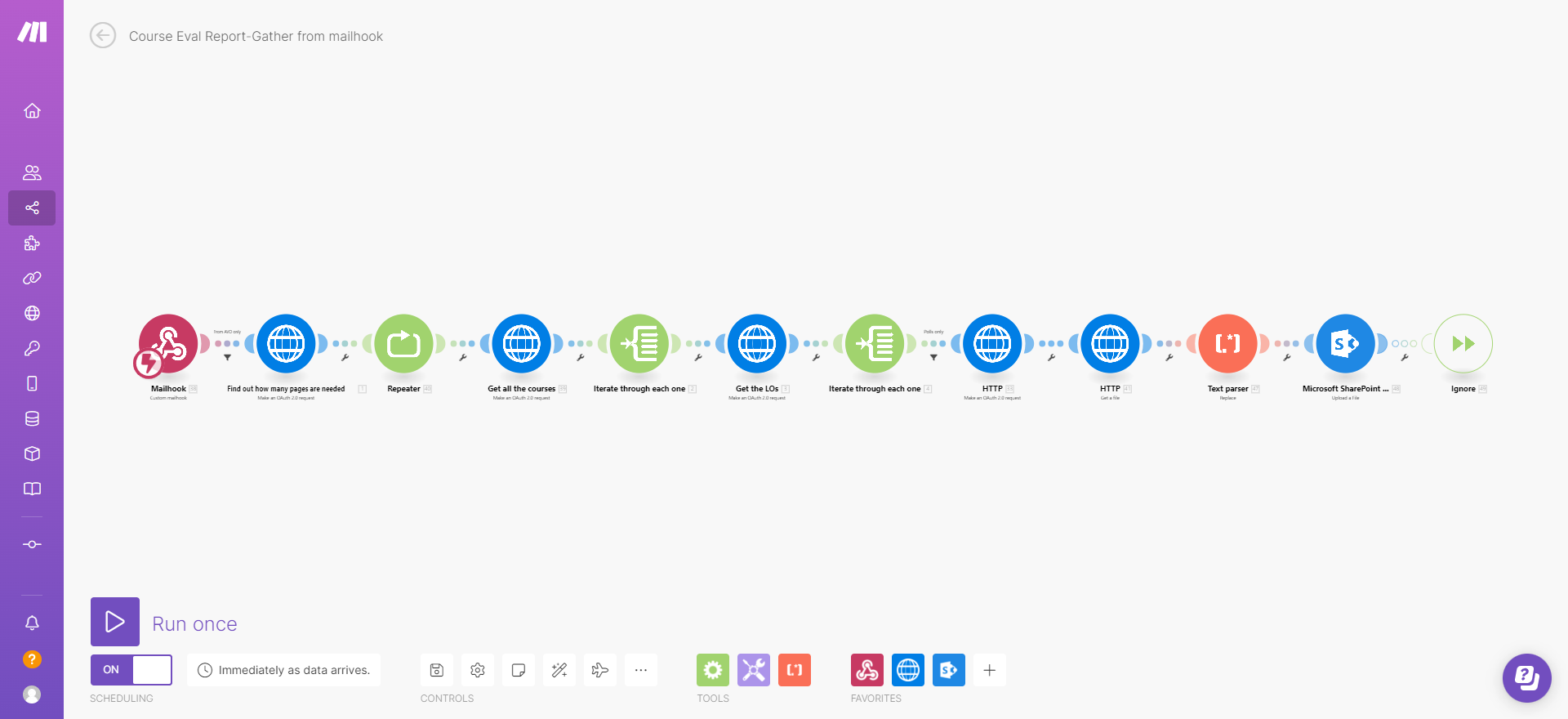
Below I’d like to share with you my approach to solving that problem by using Docebo API (I can’t share the full code of the Python script that I wrote for that, but given this outline any skilled developer should be able to create a similar tool).
My goal was to create a solution, which would automatically pull data from ALL surveys across ALL courses and save the responses into CSV files.
1 Get the list of all courses on the platform
First fetch all courses using the API
GET /course/v1/courses
2 Iterate through all courses
Then, in a loop iterate through all courses, skipping those that are not published (coursePublished == False) or deleted (courseDeleted == True)
2.1 (optionally) get course star rating value
You may want to get and store the star rating for each course for that use the API
GET /learn/v1/courses/{courseId}/rating
2.2 Retrieve the list of learning objects
To identify surveys, you need to fetch the list of all learning objects in a course
GET /learn/v1/courses/{courseId}/los
2.3 Iterate through all learning objects
In another loop, go through all LOs, skipping those which are NOT polls ('object_type' != "poll")
2.3.1 Get the poll ID
From learning objects which are polls, get the poll identifier from the id_resource field
pollId = lo[‘id_resource’]
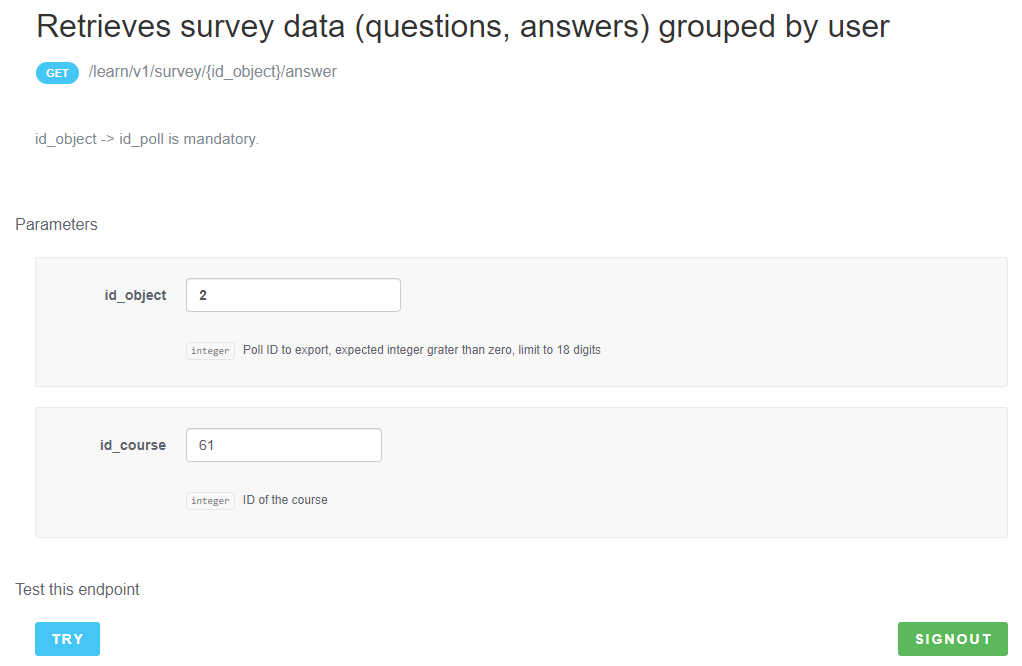
2.3.2 Fetch all answers for a poll
To get all answers use the API
GET /learn/v1/survey/{pollId}/answer?id_course={courseId}
in Python, you can now convert the received JSON to a flat table using Pandas DataFrame
df = pd.DataFrame(pd.json_normalize(courseSurveys))
Optionally, add a few columns to make the CSV file more user friendly and make it easier if you’d like to aggregate responses from several courses.
df['COURSE-code'] = course["code"]
df['COURSE-id'] = courseId
df['COURSE-category_name'] = course['category_name']
df['COURSE-type'] = course['type']
df['COURSE-title'] = course["title"]
and then save it to a CSV file:
df.to_csv(f'surveysFolder/course{courseId}-poll{pollId}.csv', index=False)
2.3.3 Repeat for each poll
If there are multiple surveys in a course, they all will be saved to separate files
2.4 Repeat for each course
In that way, you will end up with the surveysFolder containing separate files for each survey in each course :-)
NOTE, if you have your survey in the Central Repository, the poll ID (id_resource) value will be the same across all courses that are using that survey, so you will be able to easily aggregate responses from all courses which are using that survey.
I hope this is helpful.