I am a Data Analyst looking into Docebo’s data set.
I’m using python for API calls, I know how OAuth2 works and have my access token and the whole stuff to refresh the token when needed. I’m using the endpoint get/report/v1/branch_dashboard_enrollment/{id}
I have the branch id right and I do get a nice (page) set of 100 records back, the request takes about 7 seconds to complete. All good. I know how to do pagination, so I repeat my question for the next page, this is also successful.
Now my problem is : I have more then 2K pages...it would take almost 3 hours to download the set and all I’m interested in are the changes in enrollment since yesterday. As far as I can see there is no ‘last_modification_date’ or last_updated_date’ in the return where I should be able to filter on…the only filter I see (and that one works fine) is on status. But that still gives me +60K records on each status.
I need to know how many people enrolled a course in any given time in the past. So it will be a big download once and a small incremental download on a daily base The goal of the project is to get this data together with a lot more employee data into a data lake for data analytics. I’m pretty sure this is possible, the only thing that is wrong is that I’m blind and not able to see it ;-) Can anybody shed a light on it ?
Thanks a lot !
Page 1 / 1
Hey @Philippe,
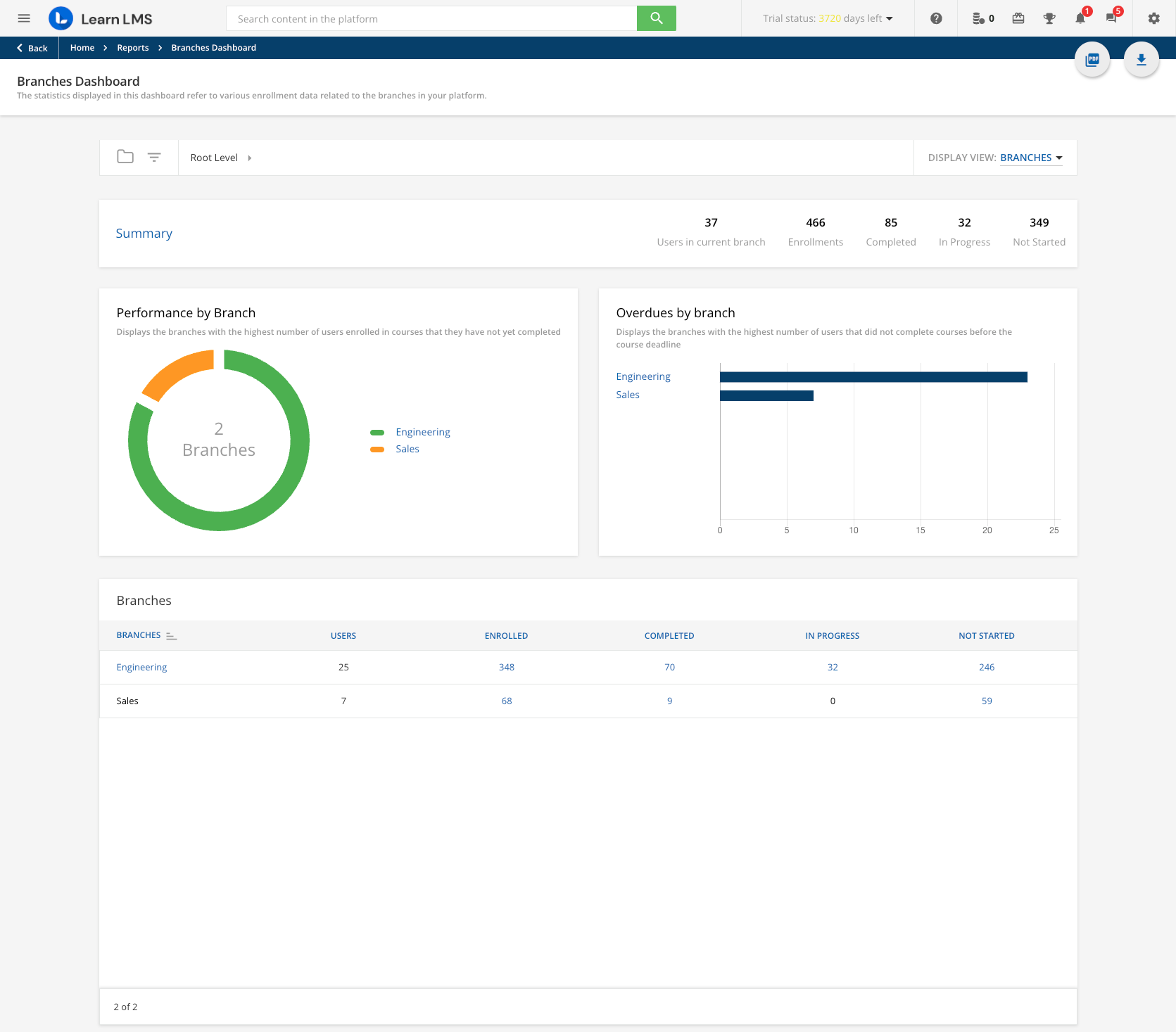
It may be helpful to have some context on this endpoint and how it’s used/why it was created, to better understand the current approach vs a better solution. If I’m in the UI, as an Admin, there is a dashboard view in legacy Reports app that allows admins to filter the on-screen dashboard by Branch. Here’s a snapshot view:
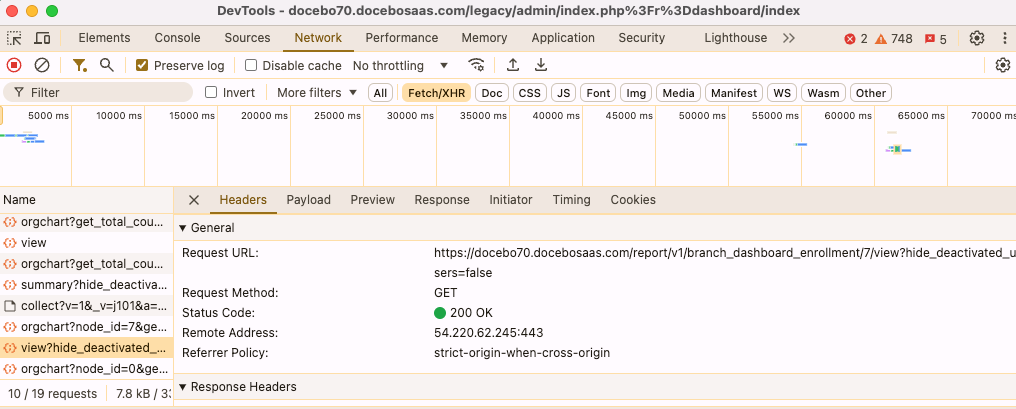
If I click on “Engineering”, you can visualize the endpoint called in the console view of my browser:
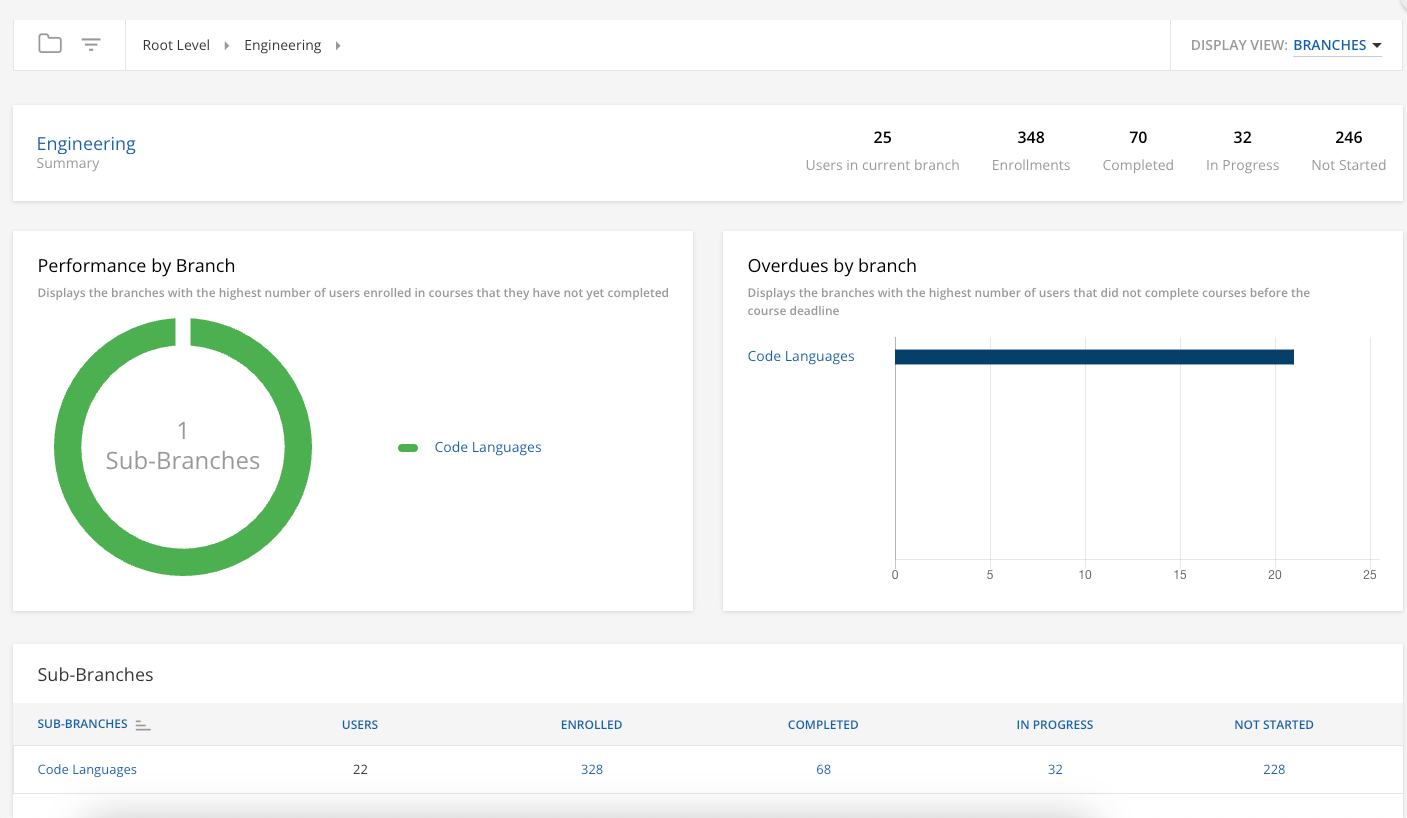
On screen after I click that Branch I get the “id” breakdown and visual dashboard view below. I assume it’s the same type of data you’re working with or similar:
Of courses there are other ways you could use this endpoint but I’d argue this is it’s main purpose, and to paginate as the user moves forward is no problem performance wise with that intent in mind. (who’s going to click 1,000 times anyway, maybe they will?)
I need to know how many people enrolled a course in any given time in the past. So it will be a big download once and a small incremental download on a daily base.
Potential Solution with newer API endpoints (more performant): Pulling Enrollment Data Using the Docebo API
API Endpoint to Use: GET /learn/v1/enrollments
This endpoint retrieves a list of enrollments for specific courses, with options to filter based on course_id, user_id, and enrollment dates.
One-Time Bulk Download (Historical Data)
You’ll need to extract all historical enrollments at least once. The API allows pagination, which is crucial given the large data size.
Quick explanation:
from/to: Defines the date range to pull enrollments (adjust to your desired timeframe)
page/limit: Controls pagination (max limit is 100 per page).
Loop through the pages to get all data.
You said you were working in Python… here’s an example of how you could format the call and script:
# Loop through pages and accumulate results enrollments = n] page = 1 while True: data = fetch_enrollments("2020-01-01T00:00:00Z", "2024-10-25T23:59:59Z", page) if not data2'items']: break enrollments.extend(data 'items']) page += 1
print(f"Total Enrollments: {len(enrollments)}")
Daily Incremental Download (New Enrollments)
After the bulk download, you can implement a daily incremental sync by pulling only enrollments from the previous day.
Be weary of rate limits…
Rate Limits:
Docebo’s API rate is 1,000 calls per hour per endpoint per IP.
Ensure your requests respect this limit.
If the volume of enrollments is very high, you may need to implement retry logic or use parallel calls to improve performance.
The goal of the project is to get this data together with a lot more employee data into a data lake for data analytics.
With that intention in mind, I would investigate Learning Intelligence, a.k.a. Learn Data, with your CSM and/or AM to get the conversation started on options. This will be the most ideal option to manage your data ingestion at scale but also with specificity in mind for the data points we’ll provide inside our data lake sync. There is an entirely separate data dictionary and library of tables beyond the Docebo API.
You could also consider pulling a custom report via API. For example, create a Users - Courses custom report and use the Date Options filter to identify enrollments for the last 30 days. You could include various other user and course fields, too. The proposed workflow would look like this:
Get the ID of the report you want the records for with GET analytics/v1/report
Start the execution process which requires the report id returned in the previous request with GET /analytics/v1/reports/{report_id}/export/csv
Check the status of the execution process, requires both report id (step 1) and id export (returned in step 2). Call this API until status = successful, GET/analytics/v1/reports/{id_report}/exports/{id_export}
Either get the report from the URL that is returned in step 3, or use step 4 to get the report in a paginated fashion, 1000 rows at a time.
Get the lines of the report, up to 1000 lines at a time. Requires id export and report id supplied above with GET /analytics/v1/reports/{report_id}/exports/{export_id}/results. This endpoint can produce 1000 rows per response, paginated.