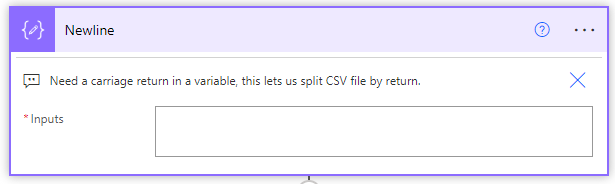
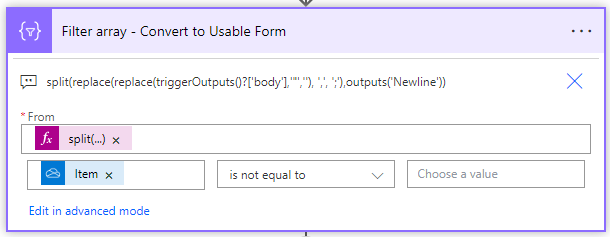
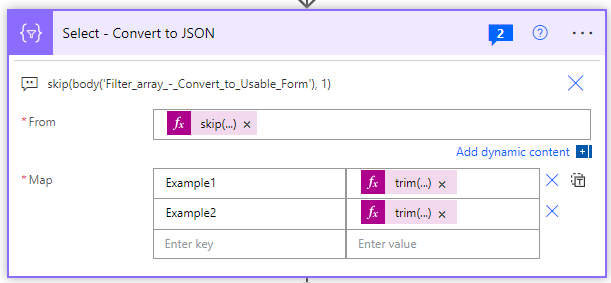
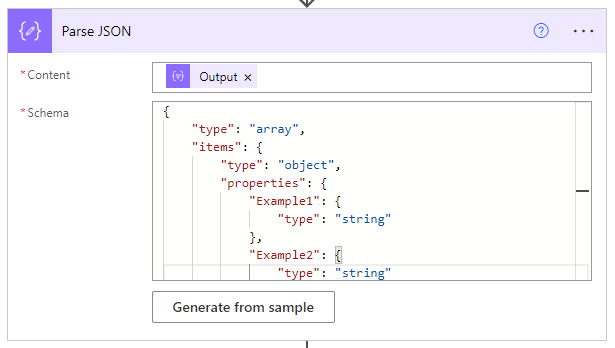
so I have a tricky API question. I am trying to make a POST call to the batch user management end point through a power automate flow. I have everything working and a call sending the following information:
{
"host": {
"connectionReferenceName": "shared_docebo-5f878a7b3d70fe89ad-5ff90adea333524d7b",
"operationId": "RosterFile"
},
"parameters": {
"body/items": [
{
"Username": "mary.smith",
"Firstname": "Mary",
"Lastname": "Smith",
"Email": "mary.smith@example.com",
"Password": "fi5Zd90S",
"Language": "english",
"Branch Name": "Demo Branch",
"Level": "poweruser",
"Timezone": "America/Chicago"
},
{
"Username": "patricia.johnson",
"Firstname": "Patricia",
"Lastname": "Johnson",
"Email": "patricia.johnson@example.com",
"Password": "ww2Do42U",
"Language": "english",
"Branch Name": "Demo Branch",
"Level": "poweruser",
"Timezone": "America/Mexico_City"
},
{
"Username": "linda.williams",
"Firstname": "Linda",
"Lastname": "Williams",
"Email": "linda.williams@example.com",
"Password": "cm7Gv20L",
"Language": "english",
"Branch Name": "Demo Branch",
"Level": "poweruser",
"Timezone": "America/Winnipeg"
},
{
"Username": "barbara.jones",
"Firstname": "Barbara",
"Lastname": "Jones",
"Email": "barbara.jones@example.com",
"Password": "ek5Sy95J",
"Language": "english",
"Branch Name": "Demo Branch",
"Level": "user",
"Timezone": "America/Winnipeg"
},
{
"Username": "sandra.martin",
"Firstname": "Sandra",
"Lastname": "Martin",
"Email": "sandra.martin@example.com",
"Password": "lv6Xv62T",
"Language": "english",
"Branch Name": "Demo Branch",
"Level": "user",
"Timezone": "Asia/Seoul"
}
],
"body/options/change_user_password": true,
"body/options/update_user_info": true,
"body/options/ignore_password_change_for_existing_users": true,
"body/options/force_create_branches": false,
"body/options/send_notification_email": false
}
}
The only problem is that I keep getting the following response:
{
"statusCode": 200,
"headers": {
"Transfer-Encoding": "chunked",
"Vary": "Accept-Encoding",
"Request-Context": "appId=cid-v1:0c37065f-4d7c-47cf-af06-96cd9a75949d",
"x-ms-function-status": "OK",
"Date": "Mon, 10 Apr 2023 15:19:58 GMT",
"Content-Type": "application/json; charset=utf-8",
"Content-Length": "26"
},
"body": {
"message": "Hello World"
}
}
And no users get imported. Why? What am I doing wrong?