Hello good people !
I am a Data Analyst looking into Docebo’s data set.
I’m using python for API calls, I know how OAuth2 works and have my access token and the whole stuff to refresh the token when needed.
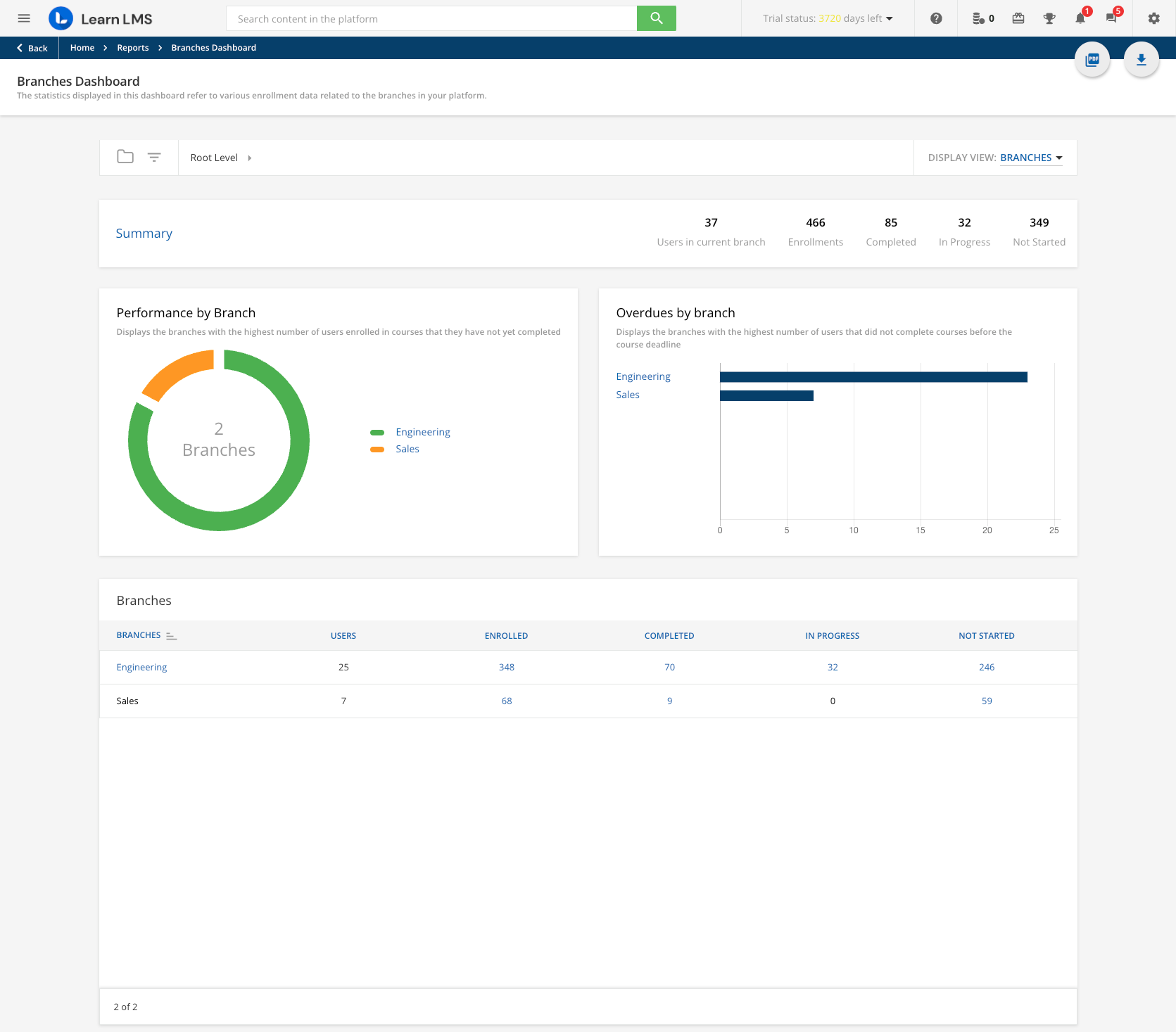
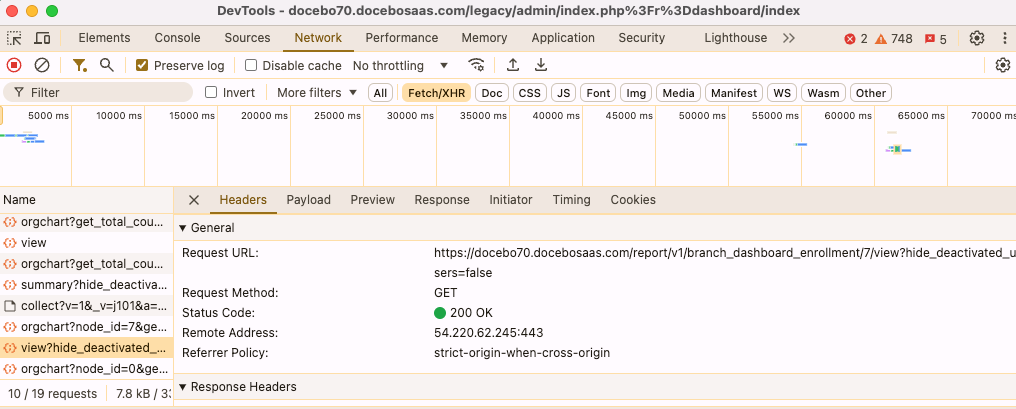
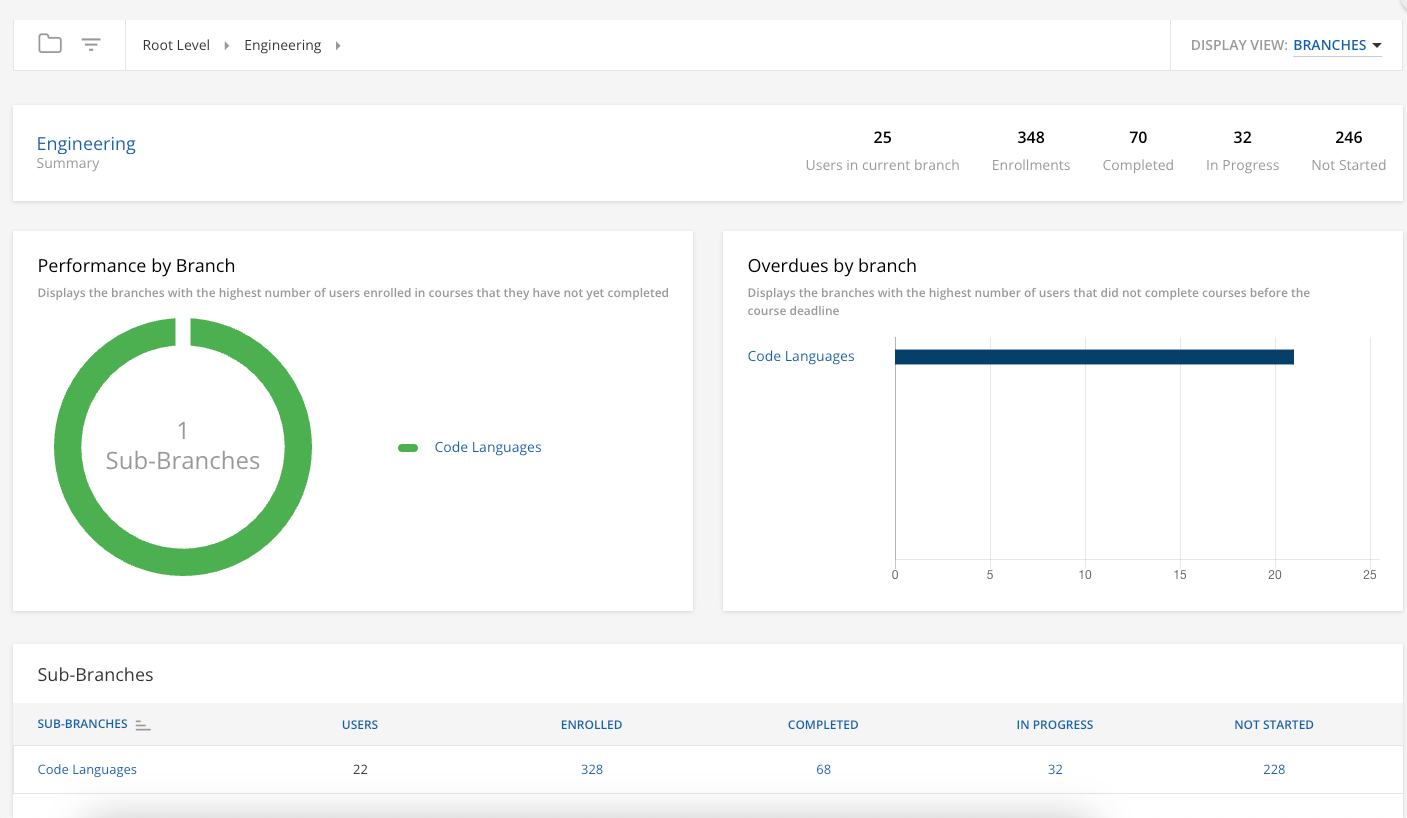
I’m using the endpoint get/report/v1/branch_dashboard_enrollment/{id}
I have the branch id right and I do get a nice (page) set of 100 records back, the request takes about 7 seconds to complete. All good. I know how to do pagination, so I repeat my question for the next page, this is also successful.
Now my problem is : I have more then 2K pages...it would take almost 3 hours to download the set and all I’m interested in are the changes in enrollment since yesterday. As far as I can see there is no ‘last_modification_date’ or last_updated_date’ in the return where I should be able to filter on…the only filter I see (and that one works fine) is on status. But that still gives me +60K records on each status.
I need to know how many people enrolled a course in any given time in the past. So it will be a big download once and a small incremental download on a daily base
The goal of the project is to get this data together with a lot more employee data into a data lake for data analytics.
I’m pretty sure this is possible, the only thing that is wrong is that I’m blind and not able to see it ;-)
Can anybody shed a light on it ?
Thanks a lot !